何かと話題のChatGPT
最近、何かと耳にしたChatGPT。自分も少し使ってみてはいたのですが、検索結果の真偽性はともかくとして、やはり会話形式で応答があるのはなんとなく人にやさしい感じがします。
回答の仕方も人とチャットしているかのように自然だし、プロンプト的なものを使ってちょっとしたキャラクター付けも出来るみたいだし、そしてAPIも公開されていて、既にいろいろ作られている方も見掛けましたので、自分もその辺を参考にさせて頂きながら、何か作れないかなと思って合間の時間でちょこちょこ弄ってみました。
とりあえずパピフォンとお話しできた
で、合間の時間で少しずつ進めて、なんとなく動作するところまで作ってみたのがこちら。
まぁ、ローコストで作ったので至らぬ点は多いのですが、なんとなく会話は成立していると思います。
会話の仕組みは簡単
仕組み自体は誰しもが思いつくであろう組み合わせです。
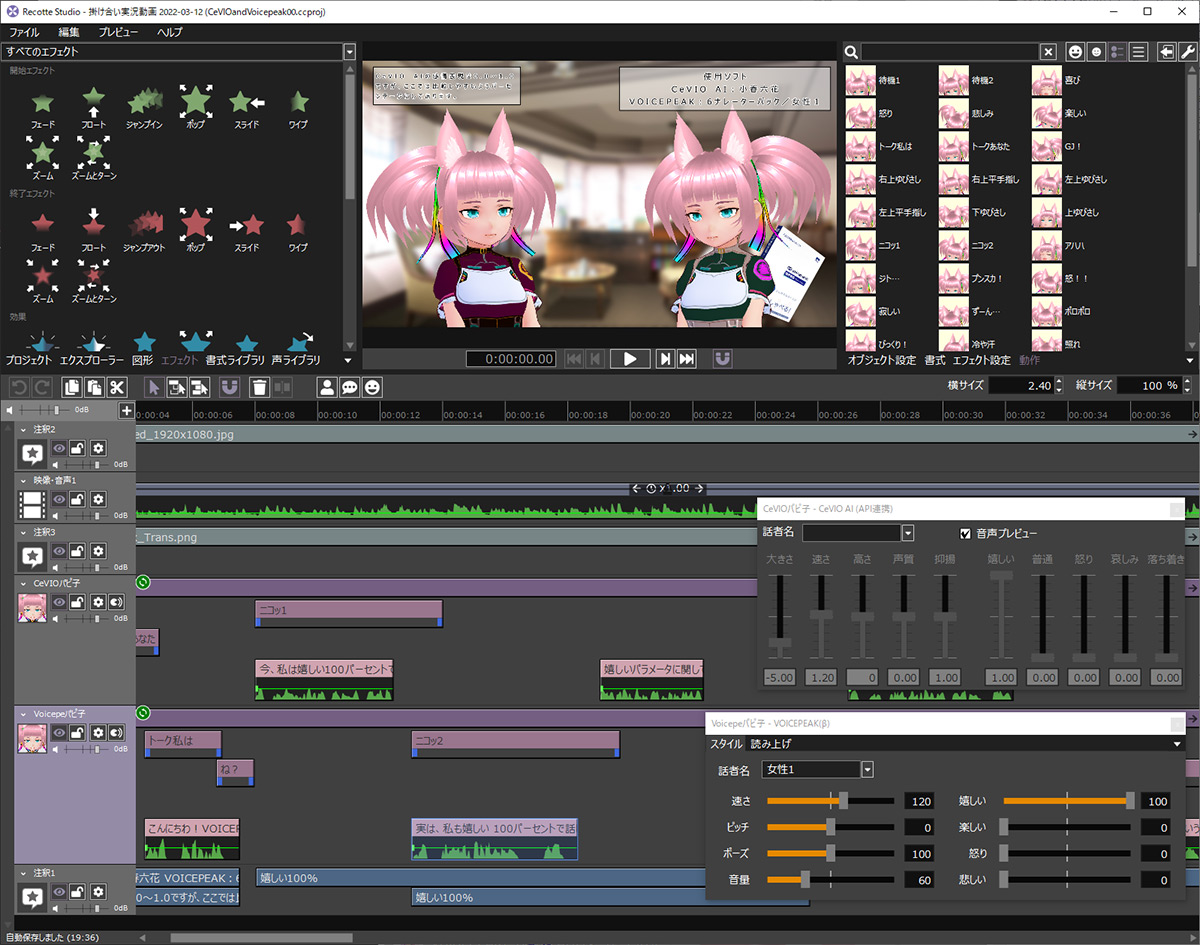
ベースはUnityでモデルはいつも通りパピフォンのVRMも読み込んでいます。で、前回のMV動画同様に目の動きにRealistic Eye Movement、口パクにはuLipySyncを今回はリアルタイム処理で使用、あと体が硬直しているとおかしいので少しだけ動くモーションを割り当てています。
で、この上に質問と回答の仕組みを載せています。
マイクからの入力を文字列にする
質問はマイクからの入力をUnity上で一旦AudioClipとして録音します。で、これをAudioClipからWavファイルに保存します。このWavファイルをChatGPTと同じOpenAI社のWhisperのAPIに投げています。他にもソリューションあるのかもですが、ひとまずChatGPTが話の起点だったので、同じOpenAIアカウントとAPIキーが使えるのが便利だなという事で。
WhisperからはWavファイルから解析した日本語文字列が返ってくるのでこれを問い掛け文字列として受け取ります。
UnityからWhisperに投げる所の実装については以下のサイトの記事が非常に参考になりました。ありがたし。
■Whisper APIをUnityで動かす
https://zenn.dev/dara/scraps/b8e2c8e994b384
問い掛け文字列をChatGPTに投げる
で、問い掛け文字列が出来た所でこれをChatGPTのAPIに投げています。この時、ChatGPTに前提として少しだけキャラ設定的なものを付加しています。なので、通常のWebから検索的に質問を投げた時とは少し違った雰囲気で返答文字列が返ってきています。動画の中で語尾にやたら「ワン!」が付いているのとかが分かると思います。
ChatGPTに投げる部分の実装は以下のサイトが非常に分かりやすいと思います。
■ChatGPT APIをUnityから動かす。|ねぎぽよし
https://note.com/negipoyoc/n/n88189e590ac3
そう、いつもお世話になっているLuppetの作者様の記事です。つよい。
ChatGPTの返答をCeVIO AIでキャラクタの声にする
ChatGPTから返された(キャラ付けされた)返答文字列は一旦テキストファイルに出力しています。で、今度はこれをキャラに喋らせる為にCeVIO AIにかけるのですが、ちょっとここで細工が必要になりました。
CeVIO AIにコマンドラインからテキストファイル→キャラの発声Wavファイルが出来れば良かったのですが、標準ではその機能な無いようです。ただ、CeVIO AIはVisualStudio 2019の環境で使えるDLLの情報を公開してくれているので、今回はこれを使って指定したテキストファイルからキャラの発声Wavファイルを生成するコンバータを別途作成しました。
作成しました…とはいえここに上がっているサンプルコードをちょっと改造してやっただけなのですが(^^; とても参考になりました、ありがとうございます。
■CeVIO AI ユーザーズガイド | .NETアセンブリとして利用
https://cevio.jp/guide/cevio_ai/interface/dotnet/
キャラクタの発声WavファイルをUnity上で再生する
CeVIO AIから出力されたWavファイルが出来たらそれをUnity側にAudioClipとして読み込み、そのAudioClipをUnity上に用意してあるAudioSourceオブジェクトに設定してPlay()すれば応答完了となります。AudioSourceにはuLipSyncの設定がされているので発声を解析しながら適した口の形状で口パクしてくれます。
キャラの性格付けが面白い
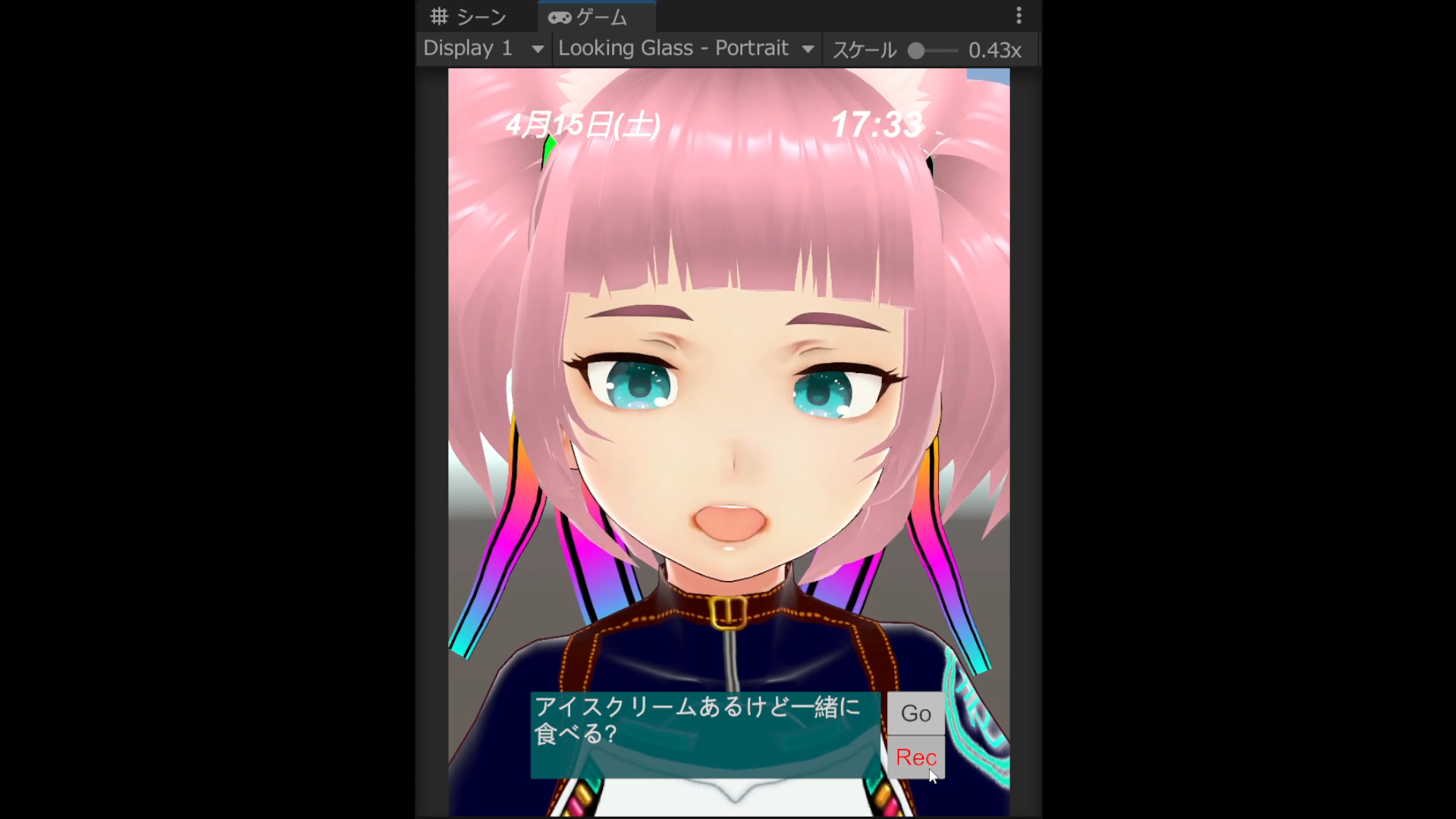
動画の中ではパピフォンが(事情を知っていると)好き勝手喋ってますが、実はChatGPTに前提(content)として投げている設定は次の文字列だけだったりします。
「"あなたはパピフォンという名前の16歳の少女です。元気よく話します。喫茶店でアルバイトをしています。犬が大好きです。おすすめの犬種はボストンテリアです。語尾に「ワン」をつけて下さい。"」
動画の中では最初に自己紹介をしてもらっていますが、そこはこの設定に忠実に述べているようです。
2つ目の質問は「普段は何をしていますか?」と既に無茶振りな感じの質問をしていますが、「普段は学校に行っている」とか「学校が終わるとアルバイト」とか返ってきて驚きました(^^;。直結するような設定は無いのですが、ChatGPTが知っている"元気の良い16歳の少女"の普段がこんな感じで記憶されているのでしょうか…。
また、「犬が大好きです。」の設定の影響で「家に帰ると犬と遊んだり散歩に行ったりする」という回答が導かれているようです。「休日は映画を見たり旅行に行ったりする事もある」とかは、もうキャラを作った僕すらも知らなかった設定です(笑)。
3つ目の質問はうちのリアル娘ちゃんが近くでアイスクリームうんぬん…喋ってたのを聞いて、咄嗟に質問したという無茶振り極みのような質問です。生きてるうちにAIにアイス食べるか聞く時代がこようとは・・・(^^;。でも、ここでもちゃんと「16歳の少女で元気よく話す」という設定が効いているのか、「アイスクリーム大好き」とか「一緒に食べると嬉しいです」とか言われちゃいます。まるでこちらの心情まで察してくれているかのように…スゲー。
課金の話
そんな感じでキャラ付けも出来るので、トコトン細かい所までの設定や膨大なシナリオを決めて、キャラクターとして細かく制御も出来そうではあるのですが、そうするとちょっと気になってくるのがトークンの使用量。
ChatGPTはただWeb版を使うだけなら無料ですが、APIを使うにあたってはAPIキーを取得して作成したアプリケーションに埋め込む必要があります。このAPIの取得にはChatGPT Plusへ加入が必須となっており、その料金は月額20ドル(4/17日現在、日本円で2600円ぐらい)となっています。
加入直後は数ドル分のトークンが付いてくるので、それで充分簡単なアプリの動作チェック等は行えますが、消費後もしくは有効期限が切れた後は、使用したトークンの量に併せて課金が発生します。
トークンってなんやねん・・・って事になると思うのですが、端的に言ってしまえば送受信する文字列の量なのですが、この辺の計算の仕方が英語と日本語で違ったりで、日本語の方がやや使用量多めになる傾向があるようです。
トークン使用量の注意点については以下のサイトの記事が分かりやすかったです。
■ChatGPTのAPIの利用料金を詳しく解説!使い方次第でトークン増大で高額費用も
https://auto-worker.com/blog/?p=7459
■Chapter 09 OpenAIのAPI料金の計算方法
https://zenn.dev/umi_mori/books/chatbot-chatgpt/viewer/how_to_calculate_openai_api_prices
要は細かいキャラ付けや膨大なシナリオを設定する事は出来ますが、それらはChatGPTに質問を投げる度に毎回送信する必要がある為、トークンの使用量が跳ね上がる事になります。また、過去の質問に関連した会話も出来ますが、それにはその過去のやり取りを添付して、新しい質問を投げる必要があるので、これも処理の仕方によってはトークンの使用量が爆増する事になりそうです。
まぁ、とはいえ1000トークンで0.002ドルだと個人で遊んでる限りは結構使っても大した額は行かなそうではあります。どうしても怖ければOpenAIのサイトから使用量のリミッターが掛けられるようになっているので、それを設定しておけば安心かと。
で、ちょっと気になっているのが、課金はアプリケーションに埋め込まれたAPIキー→APIキーを持っているOpenAIのアカウントの支払い情報、と紐づく訳ですが、となるとうっかりアプリケーションにAPIキー仕込んだままアプリケーションを公開しようものならトークン使用量の請求は全て作者に来る訳です(^^; 独自の課金システムでも持っているなら良いのかもですが、個人でちょこっと遊ぶ分にはそんな事も出来ないしなぁ…という所です。
アプリケーション側で入力欄作ってAPIキーの取得をユーザにお願いして入力して貰うという手もありそうですが、これはこれでChatGPT Plusの加入が必須になるので使える人は限定的になりそうです。
この辺そもそもどうするのが一般的なのかもよく知らないのでちょっと興味ある所ではあります。
合成音声側の話
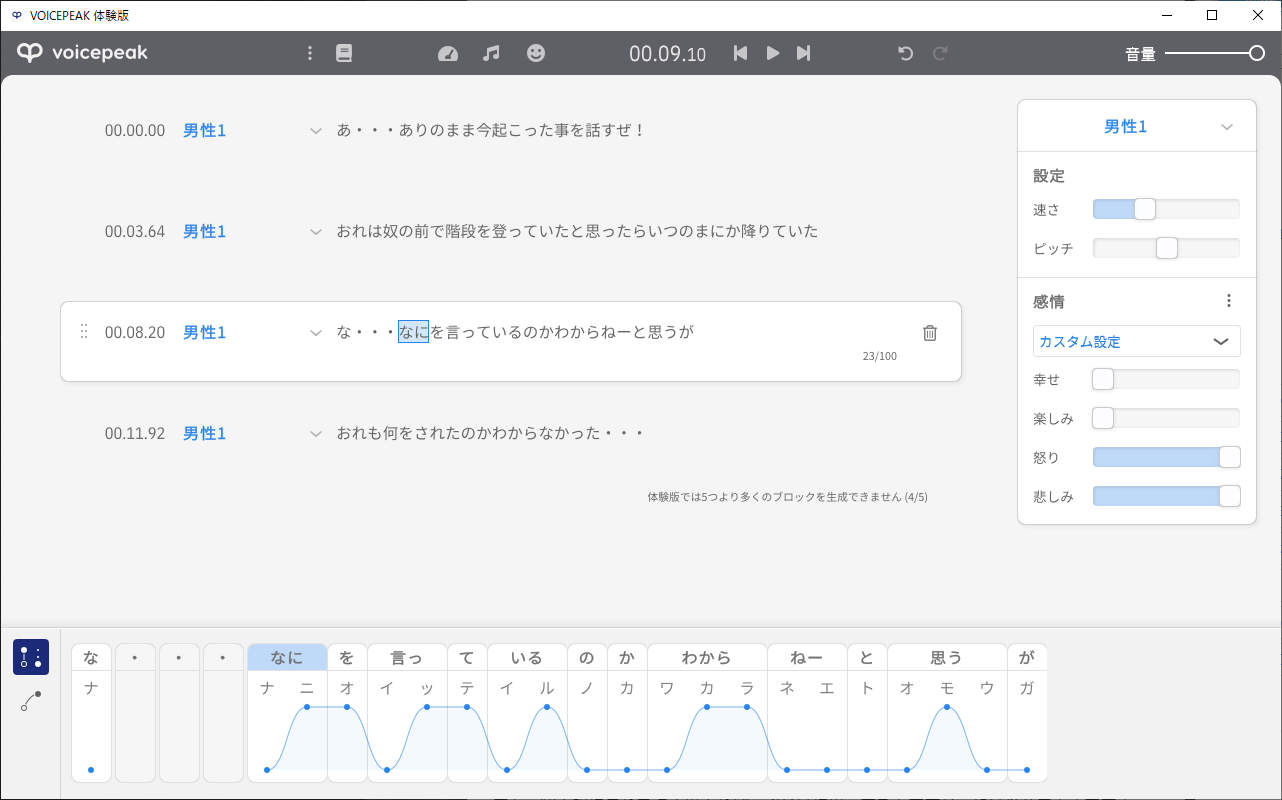
実は当初、ChatGPTからの回答の読み上げにはCeVIO AIでは無く、VOICEPEAKを使おうと思っていました。というのもVOICEPEAK本体にコマンドライン実行機能がありまして使用が手軽そうだったので。以下のサイトを参考にさせていただきました。
voicepeak v1.2.1のコマンド – takashiskiのブログ
https://takashiski.hatenablog.com/entry/2023/01/13/235249
今回のアプリケーションの中には既にこのコマンドラインの書式でVOICEPEAKを起動するクラスを実装済みで、現にWavファイルも出力されるのですが、この出力されたWavファイルで躓きました。
ちょっと原因がまだ確定していないまま放置になっているのですが、実行時に作成されたWavファイルをUnityのAudioClipに読み込む際に、どの読み込みアセット使っても尽く失敗するんですよね…。Wavっててっきりベタしか無いものだと思ってたんですが、エラーの内容やヘッダーの情報見る限り、圧縮か何か掛かっている雰囲気がありました。ACMって奴がそれなのか…という気もするのですが、情報が少なく詳細不明。もしこれならオプションで非圧縮に出来ると良かったのですが…。
で、今回のアプリケーションではパピフォンを使っていたので、よく考えたらいつも声当ててるのCeVIO AIの小春六花だなーという事でCeVIO AIに変更。調べたら、CeVIO AIは本体にはコマンドライン実行機能は無いようなのですが、前述の通り、CeVIO AIとのやり取りを仲介してくれるDLLの仕様が公開されている為、こちらを利用してコマンドライン用のコンバータ(exe)を作成した流れになっています。CeVIO AIから出力されたWavファイルはUnityのいずれのアセットでも普通に読み込めたので、課題自体はこれでクリア出来ました。(VOICEPEAKのWavはいずれ調べてみようかな…)
画面が縦長な理由
元々このアプリケーション、手持ちのLooking Glass Portraitにパピフォンを表示しようと思って弄ってたアプリケーションだったんですよね。でも、画面の設定が上手くいってなくて何故か横の解像度だけが2倍になってしまうという現象に頭を悩まされています…orz。
裸眼立体視のキャラとお話し出来たら「そこにいる感」凄そうなんですけどねー。これはもうちょっと先になりそうです。
今後の動向
ここまで作っておいてなんですが、OpenAI社の方で今後、音声や画像による入出力が出来るようにする計画があるらしいので、キャラは兎も角、質疑応答に関しては標準で出来るようになる日は遠く無さそうです。音声認識についてはWhipserあるし、回答作成についてはChatGPTがあるので、最後の合成音声部分はどういう実装になるのかなーというのが気になる所ではあります。
単純に考えればAmazonのアレクサのように単一の声(とは言え最近男声も追加されましたが)による応答で充分機能は果たせるのですが、声まで何か弄れるようなギミックがあったら面白そう…というか既存の合成音声ソフトにも影響出そうで怖くはあります(^^;。
まぁ、しばらくは動向を注視しておこうかなぁと…。