自宅療養を駆け抜けろ
久しぶりの更新となりますが、昨年11月頃からひっそりと作っていたMFゴーストのOP曲でもあるJUNGLE FIRE feat. MOTSUの方がまとまりましたので、Youtubeの方に上げてみました。
今から3か月弱ほど前の11月ですが、世はコロナ明けムード全開の中、どこで貰ったかコロナを患いました…(^^;。幸い症状は無茶苦茶軽くて、のどの痛みすら無く、熱も一瞬出ただけで収まってしまったのですが、外をウロつく訳にもいかず、折角の連休も動けないので、これはもう打ち込みでもして憂さ晴らすしかない…という事で楽譜@ELISEを漁りだしたのが最初でした。
実は昔から頭文字Dが好き(唯一Blu-ray Box揃えた)で、昨年末まで放送していた後継作品のMFゴーストを楽しみに見ているタイミングでした。やはり車とユーロビートの組み合わせ熱すぎる、最高だよなーと。
で、そんなタイミングで以前は無かったハズのJUNGLE FIREの楽譜が検索に引っ掛かり、これはやれというお告げかなと勝手に思い込み、出掛けられない連休をつぎ込んで作り始めたのでした…。
あ、ただ、復帰後は基本的に家族が寝静まってからが作業時間、昼間は嫁様、娘ちゃんとの時間を削らない、なるべくコンパクトに仕上げるというコンセプトは変わっていません^^; なのでかけられる時間も限られてますし、がっつり作り込める訳でもないのでゆる~く見て頂ければ幸いです。
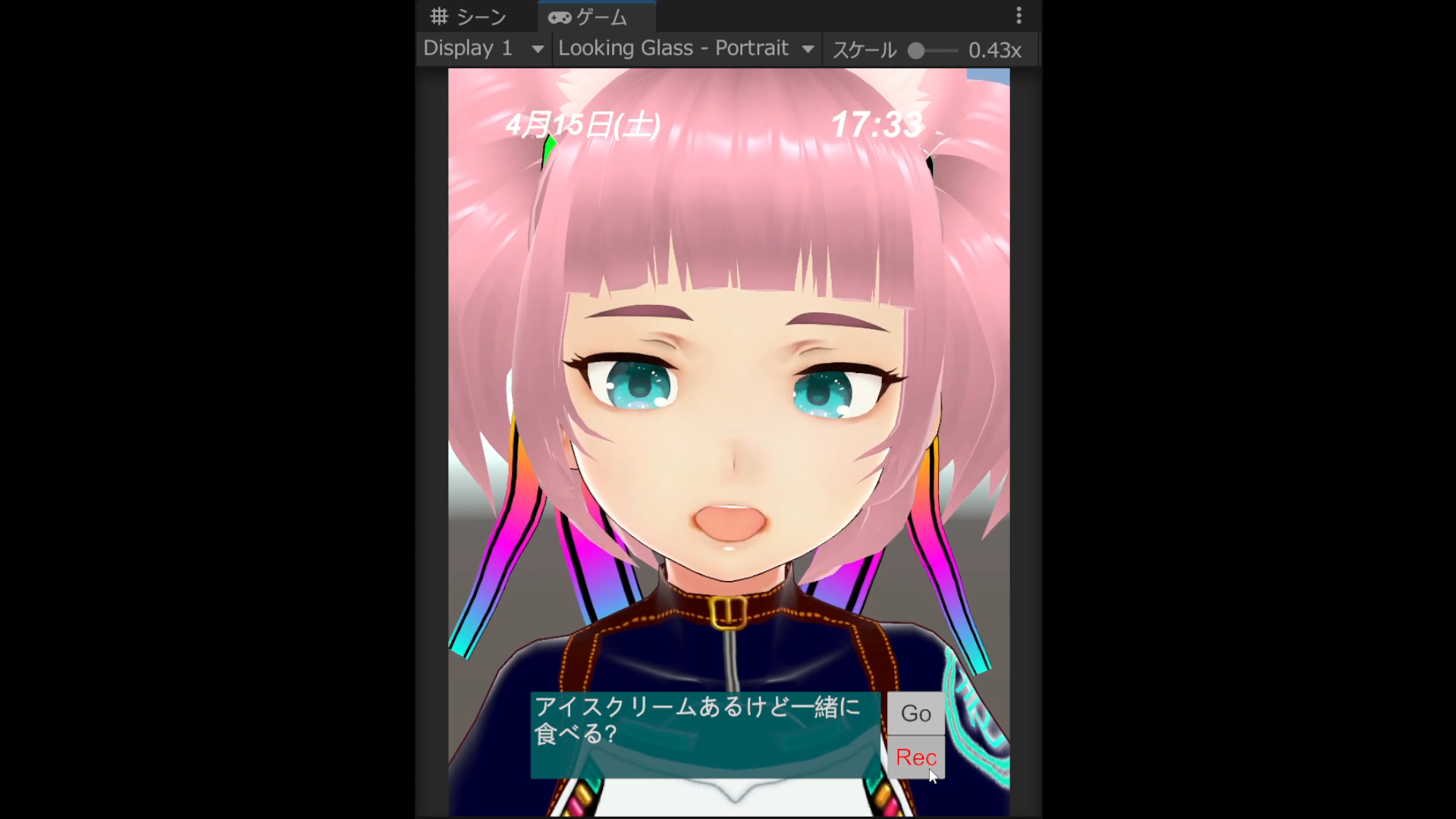
歌い手は京町セイカとNinezroで
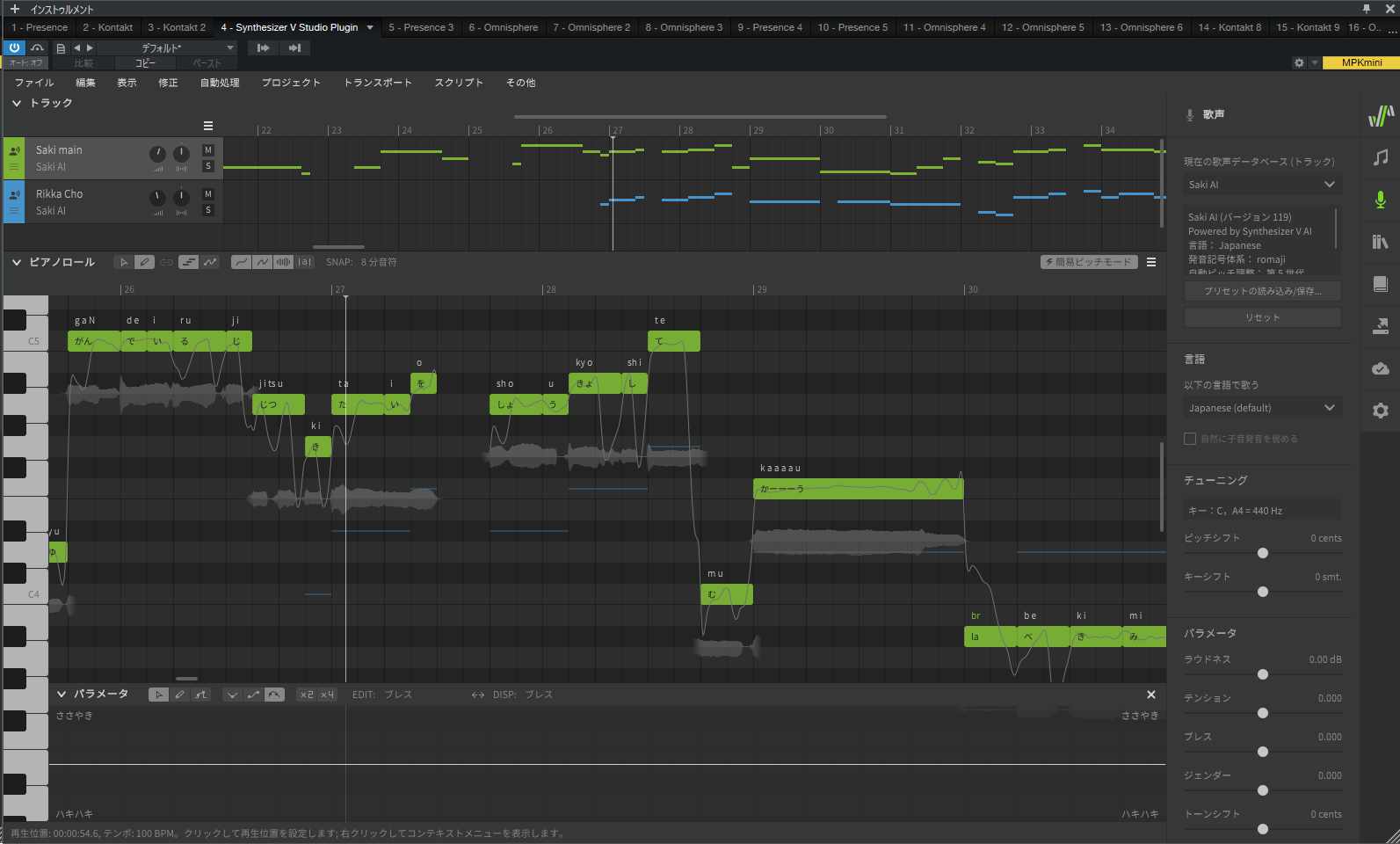
実は着手する直前に某サイトのセールでSynthesizer V AI Ninezeroを購入してたんですよね。以前より若い感じでは無くて、渋いおっさん声(失礼)の歌唱ライブラリ欲しいな、とずっと思ってたので。丁度これが10月の後半にSynthesizer Vが対応したラップモードに対応しているという事もあって、ご存じの通りMOTSUさんが捲し立てるパートが多いJUNGLE FIREにはピッタリと思いまして、いろいろタイミングが合致したな、と今思えば感じます。
メインボーカルのSynthesizer V AI 京町セイカは原曲の芹沢 優さんのイメージに手持ちのライブラリの中では一番近いのかな、という所で選びました。芹澤 優さんが声優さんという事もあってか、やや高いオクターブの所で力強く歌える必要があると感じ、それにマッチした感じでしょうか。
Synthesizer Vのラップモード
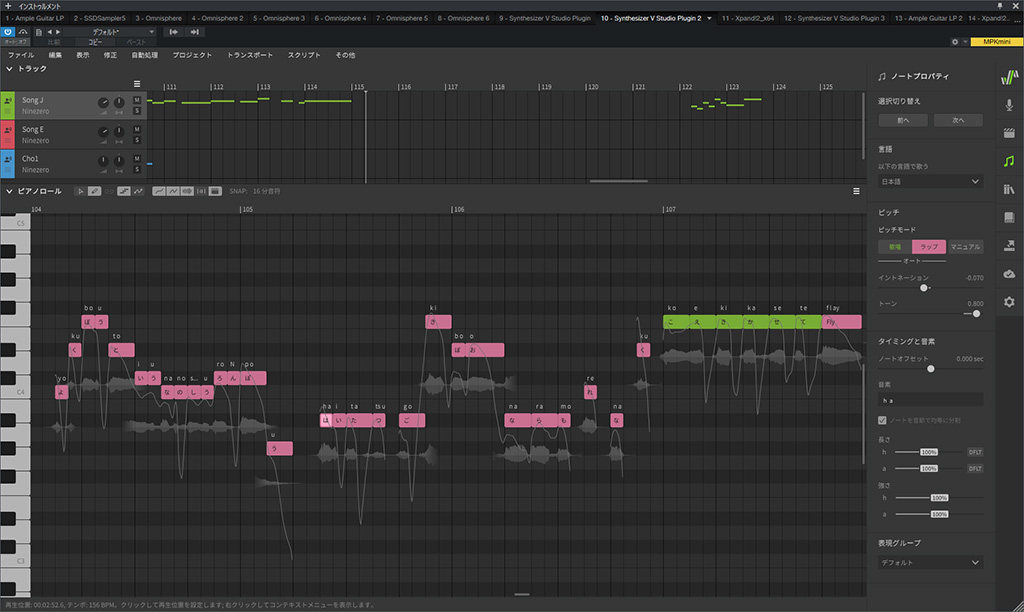
10月末に実装された機能という事もあって、初めて使ってみたのですが、まぁ、良く出来た機能でこの機能無しではまともに出来たかどうかも怪しいな…といった印象です(いや、今もまともか分かりませんけど…)。譜面としては同じキーの音符が並ぶ所も、ラップだと微妙にイントネーション的なものが変わってくるので都度調整の必要があるのですが、ラップモードにすると結構上手い具合に合わせてくれました。
勿論、それでも完璧とまでは行かないので、手動で調整はしていきましたが、あると無いでは作業量が全然違ったと思います。
音源周りについて
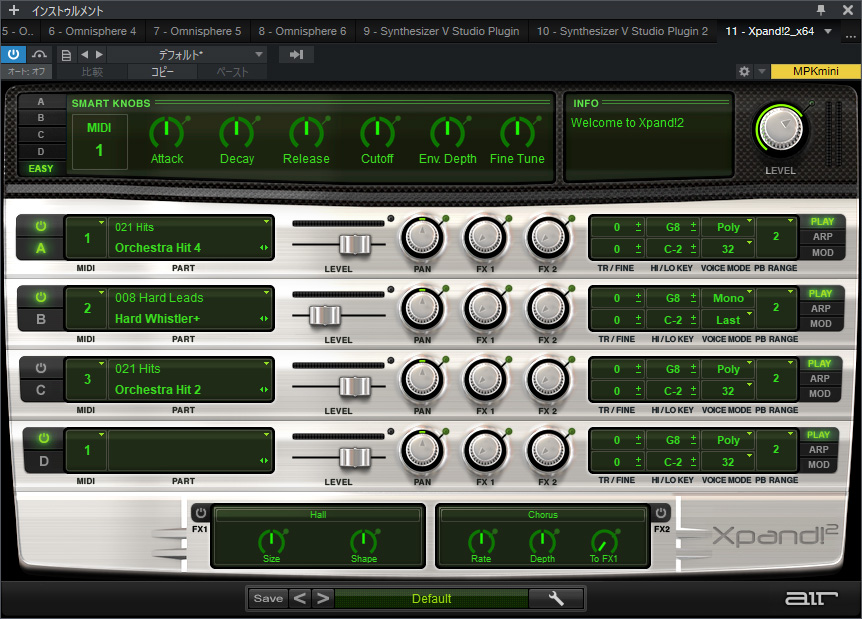
ユーロビート系の曲初めてだったので、いざ作業始めてみると音源がマッチしない部分があるな、と。ユーロビートの代名詞的なSuper Saw系の音に関してはOmnisphere 2が使えそうなの幾つか持っててくれたので良かったのですが、オーケストラヒットっぽい音が見当たらず、こちらに関してはXpand!2が幾つか持っていて安価、という情報を経て新規に導入しました。BlackFridayの時期だったのもあり、これだけの音源を10ドル程度で買えちゃう脅威のコスパでした…。
もう一つ困ったのがドラム。ここまでポップスやロックはSSD5に頼りっぱなしだったんですけど、ユーロビート系のドラムってなんか特殊ですよね…。SSD5もElectric系はあるんですが、ちょっと違うかなーというのもあり…。
どうしたものかと思ってたのですが、Xpand!2を買った際にギフトでDrumSynthというプラグインを貰っていまして、こちらが結構イメージに近い音を持っていたので、ドラムトラックもう一つ作ってSSD5と組み合わせ使用しました。
エフェクタについて
今回、新たにいくつかのエフェクタを導入してみました。Wavesのディエッサー「DeEsser」、ダブラー「Doubler2」とiZotopeのボコーダー「VocalSynth2」です。
効果大きかったなと感じたのはDoubler2でしょうか。合成音声ボーカルは出力すると単音はきれいなのですが、ステレオで出そうがリバーブ系で空間を設定しようが、なんとなく普段耳にする楽曲とボーカルの広がりが違うなと感じるところが今まであったのですが、Doubler2で調整する事で少し厚みを付けたり、パンはセンターにいるけど声が広がってくる感じが付けられて、個人的には結構理想に近づけた感じがします。
VocalSynth2は今の所「ジャンゴパイヨー」のロボットボイスのワンポイントの使用です。ボコーダー持っていなかったので、こればかりは新規に入れるしかないな・・・という事で見繕ったのですが、VocalSynth2自体はかなり多機能で他にも色々使い勝手有りそうなので、今後色々弄ってみようかなと思っています。ちなみに元の声はこれもまたNinezeroからVocalSynth2に入れています。
JUNGLE FIRE譜面の謎

そんな感じで少しリソースを増やしたりしながら打ち込み作業をしてたのですが、最後まで残ったのがドラム譜の下にあるパーカッション譜。正直に言いますが、未だにこれ何を鳴らすのが正解なのか、全然分かっておりません(汗。
原曲も何度も聴いてはみてはいるのですが、よく分からず…。パーカッション譜では×印になっているのと原曲ではかなりシャカシャカ言っているので、オープンハイハット系の何かではないかという気もするのですが…。譜尾が下向いてるのでフロアタム系?でも幾ら何でもこんなに叩かないだろうしなぁ…という所で何が正解なんでしょう?
音源から映像へ
音源が大まかに出来たのが12月中旬頃だったでしょうか。映像の方も前回同様にUnityで作り始めたのですが、前回一度作ってみて反省点として、キャラをあまり動かし過ぎると意識がそっちに行ってしまって曲が頭に入ってこないな、というのがありました(今更)。なので、今回は当初から比較的狭いシーン、かつモーションも歩いたり走ったりはせず、その場で仕草、せいぜいダンスというぐらいに映像の方はコンパクトにまとめる方針で始めました。
Unityのアセットストアで某スポーツカーを購入した辺りで派手なレースシーンも思い浮かべたのですが、そこは本家のMFゴーストの方でハイクオリティなの(※)が見れますし、Unity上の車の挙動制御とかにまで手を出すと時間いくらあっても終わらない気がして今回は避けました^^;
※Youtubeにノンクレジット版が公式にアップされているのに併せて、奇しくも(?)この動画の公開予定日の翌日2024年1月26日に発売されるBlu-rayにも収録されているようです。
カジュアルな衣装が欲しい

スポーツカーのモデルに関してはGame Ready 3D Models様の「Sports Car 012815SSCR」を使わせて頂いています。他にも多くのハイグレードな車モデルを販売されているようですが、権利の関係か、「トヨタのハチロク」みたいな表記は一切なくて単にスポーツカーとなっているのでここではそれに準じます^^;。Unityのアセットストアに並んでいる段階では色がグレーだったんですが、これはなんとなくマテリアルは赤に変えてあります、なんとなく。
車に合わせて舞台としてサーキット的なモデルでも導入するかとも思ったのですが、先の通りレースシーンとかは避けてたので、今回はガレージのモデル(Xiro様のMobile Garage)を見つけてそちらを使用させて頂いています。天井に窓があり、良い感じ太陽光が差し込むのがポイント高いです。
今回、キャラクタに関しては声色の関係からパピ子を使うことを決めていたのですが、その組み合わせでスポーツカーに合う衣装ってどんなだ・・・と少々悩みました。参考がてら、booth眺めてる際にYSSS.様の「ミリタリーカジュアルセット」の衣装を見つけまして、これならキャラにも車にも馴染みそうだ、という事でそのままこちら購入して使わせて頂くことにしました。ラフに着た感じでも、ダンスしても干渉も少なくて破綻した感じにならず、とても使い勝手良かったです。他の場面でも使わせてもらおうかな、と。
動画の編集環境をDaVinci Resolveに変更
最近、ちょっと思う所あって、今回は動画の編集にいつものVEGASではなく、Blackmagic社のDaVinci Resolveを使いました。思う所っていうのは、動画にAfterEffectで入れるような効果(特にモーショングラフィクス)ってAfterEffect以外じゃ作れないもんだろーかと前々から思っていたのですが、最近、DaVinci Resolveに統合されているFusionとhitFilmの名前を知る機会があり、今回DaVinci Resolveの方を使ってみた次第です。
最初、操作の違いを覚える所に少し時間は割きましたが、それ以外は特に問題なく、複数クリップの同時編集性の高さとかは素晴らしく感じました。特に歌詞の字幕入れる辺りはかなり楽になりました。
今回、別撮りしたSynthesizer Vのエディタの再生中画面の動画を背景として流すシーンがありますが、あれはクロマキーを使ってみました。あのシーンのみキャラを、RGB(0、0、255)のマテリアルを割り当てたSphere(光源計算無し)の中に突っ込み、その青い背景をクロマキーのブルーバックとしています。
また、同じシーンで手前側でバチバチしてるスパークはとても短いまた別の素材で、これをFusionに突っ込んでループ機能でクリップいっぱいの時間まで連続再生しています。なのでノード自体は至極単純なものです(動画のインプットノードがあってループつけてそのままアウトプットに回すだけ)。
この辺りはまだまだ実験してみた、という要素が多いですね。今後に活かせればと思います。
あまりにも使えすぎるDaVinci Resolve。実は開発元のBlackmagic社の意向もあり無料で使えたりします。有料版もあるのですが、8K編集やGPUのアクセラレート効かせるのが目的になる感じなので個人使用なら無料版で全然良さそうなのですよね。ただ、その意向に結構共感出来る部分があったので、当面使ってみて問題無さそうであれば敢えて有料版に移行しようかな、とすら思えます。
Blackmagic社の意向についてはVookさんで詳しく説明されていました。
■DaVinci Resolveはなぜ無償なのか? なぜ安いのか?
実はVEGASもPOSTグレードで買うとVEGAS Effects 5が入っていて、これが教えて頂いた所では中身はHitFilmらしく、結構それでもいいかもな、と思う所はあったのですが、HitFilm本家の方は結構サブスクリプション推しに移行しているらしく、その辺が懸念材料になってDaVinci Resolve側に傾く要因の一つになったというのもあります。最近、猫も杓子もサブスクでちょっとアレルギー気味なんですよね…自分。
そういえば
今年初めての更新でしたね、今更ながら本年もよろしくお願いいたします。
今後ですが、実はJUNGLE FIREの前に一本、曲の打ち込みは一旦終わっているものがあったりするのですが、これについてはJUNGLE FIREで学んだテクや機材を反映させたいな、と思う所もありまして一旦寝かせておこうかな、と。
DTM以外でやりたい事もスタックしてきているので、しばらくはそちらを消化して、忘れた頃にまたひっそり再開しようかと思います。ゆる~く進めます^^;